Classifier Ensembles
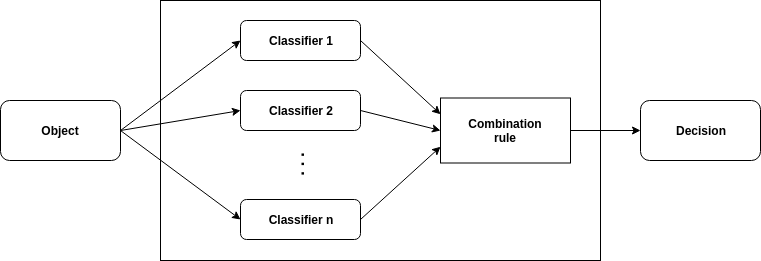
An ensemble (also known as multiple classifier system or committee) consists of a set of base classifiers whose predictions are combined to label new instances. Combining classifiers have been proved to be an effective way of dividing complex learning problems into sub-problems as well as improving predictive accuracy. A well-tuned ensemble should contain both strong and diverse base models.
Classifier ensemble diagram
Under the data stream scenario, based on the way of examples processing, the
ensembles can be categorized as chunk-based or online. The stream-learn
package implements various ensemble methods for data stream classification,
which can be found in the ensembles module.
Chunk-based Ensembles for Data Streams
Chunk-based approaches process successively incoming data chunks containing a predetermined number of instances. The learning algorithm can repeatedly process training samples located in a given data chunk to learn base models. It is worth noting that this does not mean that batch processing can only be used when new instances arrive in chunks. These approaches can also be used when instances arrive individually, if we store each new sample in a buffer until its size is equal to the size of the chunk.
Streaming Ensemble Algorithm (SEA)
The SEA class implements a basic multi classifier approach for data stream classification. This model takes the base classifier as the base_estimator parameter and the pool size as the n_estimators. A single base classifier is trained on each observed data chunk and added to the ensemble. If the fixed pool size is exceeded, the worst performing model is removed. The final decision is obtained by accumulating the supports of base classifiers.
Example
from strlearn.evaluators import TestThenTrain
from strlearn.streams import StreamGenerator
from strlearn.ensembles import SEA
from sklearn.naive_bayes import GaussianNB
stream = StreamGenerator()
clf = SEA(base_estimator=GaussianNB(), n_estimators=5)
evaluator = TestThenTrain()
evaluator.process(stream, clf)
print(evaluator.scores)
Weighted Aging Ensemble (WAE)
The WAE class implements an algorithm called Weighted Aging Ensemble, which can adapt to changes in data stream class distribution. The method was inspired by Accuracy Weighted Ensemble (AWE) algorithm to which it introduces two main modifications: (I) classifier weights depend on the individual classifier accuracies and time they have been spending in the ensemble, (II) individual classifier are chosen on the basis on the non-pairwise diversity measure. The WAE class accepts the following parameters:
base_estimator– Base classifier type.n_estimators– Fixed pool size.theta– Threshold for weight calculation method and aging procedure control.post_pruning– Whether the pruning is conducted before or after adding the classifier.pruning_criterion– accuracy.weight_calculation_method– same_for_each, proportional_to_accuracy, kuncheva, pta_related_to_whole, bell_curve,aging_method– weights_proportional, constant, gaussian.rejuvenation_power– Rejuvenation dynamics control of classifiers with high prediction accuracy.
Example
from strlearn.evaluators import TestThenTrain
from strlearn.streams import StreamGenerator
from strlearn.ensembles import WAE
from sklearn.naive_bayes import GaussianNB
stream = StreamGenerator()
clf = sl.ensembles.WAE(
GaussianNB(), weight_calculation_method="proportional_to_accuracy"
)
evaluator = TestThenTrain()
evaluator.process(stream, clf)
print(evaluator.scores)
Online Ensembles for Data Streams
Online approaches, unlike those based on batch processing, process each new sample separately. These methods have been developed for applications with memory and computational limitations (i.e. where the amount of incoming data is extensive). Online methods can also be used in cases where data samples do not arrive separately. These types of methods can process each instances of data chunk are individually and can therefore be used in an environment where data arrives in batches.
Online Bagging (OB)
Online Bagging is an ensemble learning algorithm for data streams classification, based on the concept of offline Bagging. It maintains a pool of base estimators and with the appearance of a new instance, each model is trained on it K times, where K comes from the Poisson(λ= 1) distribution. It is implemented in the OnlineBagging class which accepts base_estimator and n_estimators parameters, respectively responsible for the base classifier type and the fixed classifier pool size.
Example
from strlearn.evaluators import TestThenTrain
from strlearn.streams import StreamGenerator
from strlearn.ensembles import OnlineBagging
from sklearn.naive_bayes import GaussianNB
stream = StreamGenerator()
clf = OnlineBagging(base_estimator=GaussianNB(), n_estimators=5)
evaluator = TestThenTrain()
evaluator.process(stream, clf)
print(evaluator.scores)
Oversamping-Based Online Bagging (OOB) & Undersampling-Based Online Bagging (UOB)
Oversampling-Based Online Bagging (implemented by the OOB class) and Undersampling-Based Online Bagging (implemented by the UOB class) are methods integrating resampling with Online Bagging. Resampling is based on the change in λ values for the Poisson distribution. OOB uses oversampling to increase the chance of training minority class instances, while UOB uses undersampling to reduce the chance of training majority class instances. Implementations refer to the improved versions of both algorithms in which the λ value depends on the size ratio between classes. When the problem becomes balanced, the methods are automatically reduced to online bagging. Both methods take the same parameters as the OnlineBagging class.
Example
from strlearn.evaluators import TestThenTrain
from strlearn.streams import StreamGenerator
from strlearn.ensembles import OOB, UOB
from sklearn.naive_bayes import GaussianNB
stream = StreamGenerator()
oob = OOB(base_estimator=GaussianNB(), n_estimators=5)
uob = UOB(base_estimator=GaussianNB(), n_estimators=5)
clfs = (oob, uob)
evaluator = TestThenTrain()
evaluator.process(stream, clfs)
print(evaluator.scores)
References
Bartosz Krawczyk, Leandro Minku, João Gama, Jerzy Stefanowski, and Michal Wozniak. Ensemble learning for data stream analysis: a survey. Information Fusion, 37:132–156, 09 2017.
Nick Street and Y. Kim. A streaming ensemble algorithm (sea) for large-scale classification. Proceedings of the 7Th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 377–382, 01 2001.
Michał Woźniak, Andrzej Kasprzak, and Piotr Cal. Weighted aging classifier ensemble for the incremental drifted data streams. In Henrik Legind Larsen, Maria J. Martin-Bautista, María Amparo Vila, Troels Andreasen, and Henning Christiansen, editors, Flexible Query Answering Systems, 579–588. Berlin, Heidelberg, 2013. Springer Berlin Heidelberg.
N. C. Oza. Online bagging and boosting. In 2005 IEEE International Conference on Systems, Man and Cybernetics, volume 3, 2340–2345 Vol. 3. Oct 2005.
S. Wang, L. L. Minku, and X. Yao. Resampling-based ensemble methods for online class imbalance learning. IEEE Transactions on Knowledge and Data Engineering, 27(5):1356–1368, May 2015.